
Adventures in Dynamic Software, Visualisations, Creating a JVM Language, UI, and More
In which I detail what I've been doing this year, and some ideas for improving our software and tools.

Introduction
The state of software really bothers me, especially since I’ve seen and experienced the ways in which it could be so much better. More pleasant, more enjoyable, and less frustrating.
Throughout the previous academic year, I have allocated a (regrettably) disproportionately high amount of time to software development, exploring what opportunities may exist to address my dissatisfaction.
Here are some of the problems, briefly stated:
Software is not dynamic enough.
The organisation of source code revolves around the filesystem.
Lack of good, convenient tools for visualising data and the program.
Too much friction to get started on a new software project.
Lack of fun and adventure.
Poor-quality software everywhere.
Difficulty or inconvenience achieving adequate performance.
In this post, I will outline the recent journeys I have taken through the wonderful world of computer software. This will not be a complete account of all the interesting things I have encountered, but I hope I can provide enough encouragement for people like yourself to start building a humane future for software.
As a great announcer once said, the future starts with you.
Contents
The Problem of Bad Software
Part 1: GC-Free Languages
Rust
Carp
Zig
Zig as a Compilation Target
Part 2: Towards Dynamic Programs
The Golden Era
The Vision
Glamorous Toolkit
Project Chic
Physics-Based Dependency Graph Visualisation
Other Experiments
Structural Source Code Editor
Remarks on Community
Visual Display Brightness Control
Part 3: Going Deeper into UI Programming
Experiments Developing UI Languages
Coral UI Toolkit, 1988
chic.ui.ui3
Interactors
Part 4: Yet Another JVM Language
Why the Java Virtual Machine?
Brief Introduction to JVM Languages
Introducing Project Squawk
Dynamic Classes
Towards a Squawk IDE
More Ideas for Squawk
About the “chic” repository
Conclusion
Notice: please feel free to let me know of any errors in this article. Due to time constraints, I have not been able to thoroughly proofread it.
The Problem of Bad Software
We have no shortage of poor-quality software. Where do most people go to develop a cross-platform desktop app? Electron. Also, React Native is a popular option for mobile apps.
These perpetuate the JavaScript/HTML/CSS nightmare. These three languages have well outstayed their welcome, and are a miserable fit for the demands of modern software.
JavaScript, a language designed in ten days, is full of absurdities; it’s a joke, except it is not funny because it runs most of the Internet and many locally-installed software applications. This is a mild dystopia.
What’s worse is that, in many ways, the state of software is not drifting in a positive direction. Companies continue to invest in JavaScript:
Google V8: while impressive, I feel like this is a case of lots of resources put towards solving the wrong problem. We don’t want a faster JavaScript; we want a language that’s sane.
Visual Studio Code: the best example of an Electron app tuned for performance. With all this effort sunk into working around the limitations of JavaScript, why not build a better alternative?
Unfortunately, the prevalence of JavaScript is not the only problem. I’ve seen ample posts from Niki Tonsky demonstrating, amongst the horrors of modern UIs, the degeneration of Apple’s software, particularly due to SwiftUI.
By no means is this an exhaustive description of how software is failing to live up to its potential.
Personally, I’ve seen enough that I’m no longer content to perpetuate the “JavaScript nightmare”. I want to live in a world where we aren’t constantly battling our technology to get it to do what we want.
Part 1: GC-Free Languages
Towards the end of 2021, I had a definite desire to be free of the garbage collector. Having run into slow performance using higher-level languages, I was curious about descending the technology ladder.
Rust
I learned an ounce of Rust. With it, I produced character-picker, a simple pop-up program, designed to be triggered by a keyboard shortcut, that lets you search for and insert Unicode characters.
What do I have to say about Rust? Nothing much, but I have a few brief remarks:
Compilation is rather slow. Feedback loops are long and slow.
Hot code reloading does not seem to be much of a priority.
There is no intention of providing a stable ABI for Rust binaries.
The type system is incredibly complicated and a pain to work with. It also makes code quite verbose. That said, I appreciate the concepts of ownership and lifetimes that Rust brings to the table.
Carp
Carp is an interesting language since it is very reminiscent of Clojure. However, unlike Clojure, it compiles to C. Moreover, Carp employs ownership and lifetime tracking, similar to Rust.
After some playing around, it becomes evident that the development experience with Carp is far from mature. All code gets compiled into a single file, and it does not provide the dynamism I’m looking for. (At least this was true at the time.)
Another thing to note is that Carp is implemented in Haskell. Since this is a complex language I have no experience with, I was not going to continue my Carp journey by modifying the compiler.
Zig
I’ve heard good things about the Zig programming language, which aims to be a sane replacement for C. After looking into the project myself, I must say I approve of it myself.
Unlike Rust, I can see that work is being done to implement hot code swapping for a more interactive development experience. Additionally, Zig’s fast compilation speed is a strong selling point.
Therefore, the logical thing to do is to start working on a Clojure-like Lisp dialect that compiles to Zig and uses dynamically-linked libraries to achieve hot code swapping. In fact, I tried doing just that — the project was code-named Wave.
Zig as a Compilation Target
Rust was actually my first choice of compilation target, but I was finding it too restrictive.
Project Wave was the first time I attempted to write a compiler, and it led me down a path of learning about type systems. Things got complicated real quick. I skimmed through several papers in the process.
A sufficient amount of type system was necessary to produce typed Zig code, but I had the ambitious goal of a much more powerful type system like the one in Idris, which supports dependent types. Dependent types put constraints on the possible range of values, or something like that.
Of course, implementing a sophisticated type system is no simple task, so I’ve not made significant progress doing so. Besides, the Christmas break was almost up, and I would have to return my focus to university coursework.
Project Wave currently remains abandoned with little progress made. You’ll find the source here, but there’s nothing too exciting to see.
In the future, I may revisit the idea of compiling to a native language, but since then my interests have drifted elsewhere…
Part 2: Towards Dynamic Programs
In this part of the journey, I transition away from low-level languages, bringing my focus towards dynamic software and interfaces that leverage intuition in order to gain a quicker and stronger understanding of a system.
I will begin by giving historical context and shallowly describing the sources of inspiration that motivated the work I did in March & April. Note that there are endless details relevant to the following sections that I could not possibly convey concisely, so I highly advise visiting the sources I mention.
The Golden Era
If you've ever wanted to feel depressed about all the ways in which our current world of software could have been so much better, take a trip into the past — several decades into the past. Learn about Doug Engelbart, Alan Kay, Xerox PARC, etc.
The Dream Machine by Mitchell Waldrop is a book that gives a good historical description of the important developments leading up to modern personal computing — I thoroughly recommend it.
You'll find that much of modern computing depends on a number of key innovations that occurred within a relatively short period of time, a long time ago. A few examples include the Internet, the mouse, hypertext, the laser printer, and window-menu-icon-pointer (WIMP) UIs.
Here's the saddening part: there hasn't been much significant innovation in personal computing since the golden era; we've stagnated.
Alan Kay has said that nowadays, due to the fact that software is so easy to create, far too many people are solving the wrong problems. Additionally, old ideas are often reinvented, but done so poorly because the reinventors are not working to the same standard as the original inventors.
Therefore, don't ignore the vast computer science literature—a lot of the ideas of today are not as old as you may think.
For instance, consider collaboration on documents between distant computers. This was demonstrated in 1968 by Doug Engelbart in what is now known as "The Mother of All Demos." In addition to collaboration, this demo of a system called NLS gave an early glimpse into the power of hypertext.
Today, we have things like Google Docs. It's modern and somewhat refined. However, in some ways we have made backwards progress — when old ideas get copied, they frequently get copied poorly. NLS had a number of features that make it stand out, even by today’s standards. For example, you could view the same information in different ways (e.g. collapsing paragraphs into a single line), and there were graph views—in 1968!
The great thing about the early days of computing is that there was no strong notion of what "personal computing" is. Thus, there seemed to be more creativity and more experimentation with interesting ideas.
The Vision
The previous section was about how the amount of progress, with respect to personal computing, has been rather disappointing. As for how we can grow personal computing into its potential going forward, I find Bret Victor's work to be quite the inspiration.
Some useful resources:
I shall not elaborate further because the publications above are immensely eye-opening and profound; they provide plenty to learn about.
One of the themes Bret Victor has talked about is the need for dynamic software and dynamic representations. This leads me nicely to my experience with Glamorous Toolkit.
Glamorous Toolkit
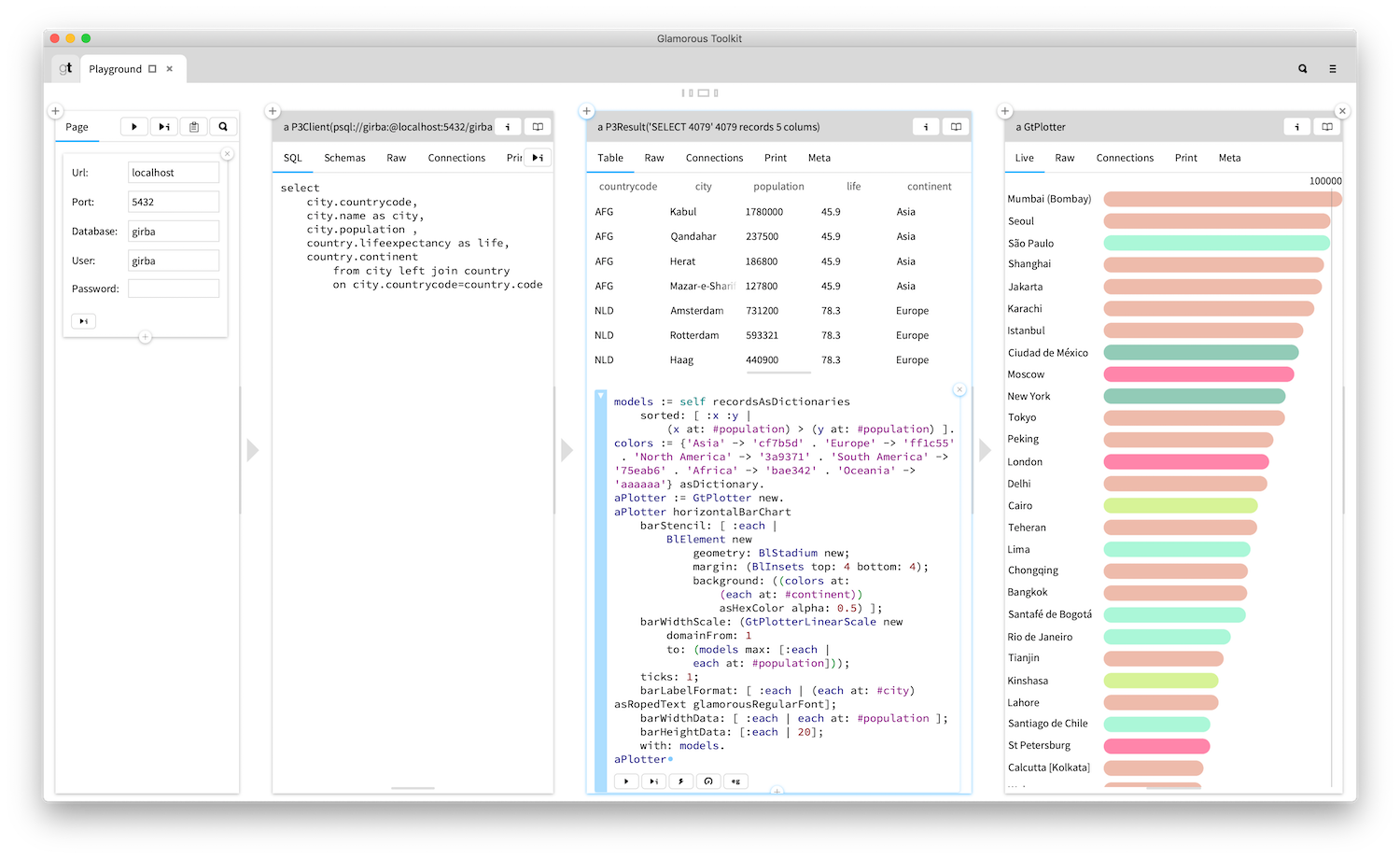
Glamorous Toolkit (GToolkit/GT) is a piece of software that I probably first heard of in 2020. My initial impression was that something deeply profound lay therein. One problem: I couldn’t understand what it was or what it did.
After browsing the website a bit, I must have dismissed it as some Java-related thing. All the speak of object-oriented programming was turning my interest away, because—at the time—I was entranced by Clojure and the joys of functional programming.
Anyway, GToolkit returned to my attention this year as a result of the video demonstrations by Tudor Girba, Gene Kim, and Eric Normand.
Glamorous Toolkit is an IDE for an implementation of Smalltalk called Pharo. Smalltalk is one of the earliest object-oriented languages, and, unlike many modern languages, the object-orientation is done well. Also, the syntax is so simple that you could learn it in a day.

Here’s a quick demo of Smalltalk on the Xerox Alto. Smalltalk is unlike other languages in that the source code is not organised around files. In fact, you are always operating on a live Smalltalk VM, using the class browser GUI to modify individual class methods. This makes Smalltalk one of the most dynamic programming environments. Rather than saving ‘dead’ files, you save an image of the state of the VM.
Glamorous Toolkit takes the dynamic nature of Smalltalk to the next level, by adding new powerful ways of visualising, navigating, and interacting with data and the program state.

GT enables a wonderful thing called “mouldable development”. In this world, the friction of developing ad-hoc tools is so low that code becomes cheap and disposable. At the core lies the premise that, for most of the problems you may want to solve, the right tools do not already exist. Therefore, it should be easy to create specialised tools for each unique situation you encounter.
One of the main things that excite me about GT is that its applications go beyond mere software development — it works as a general-purpose toolkit for understanding complex systems and organising knowledge. It resembles a missing piece of personal computing. You could even use it to write quick utility programs and views to help you manage the various data on your computer.
A key principle of GT is that you should always be working with a good visual representation, in contrast to the predominantly text-driven software development of today. GT has no traditional text-based console like the ones software developers are familiar with—because we should have outgrown that dated interface by now.
The undesirable stuff
Unfortunately, my journey with Glamorous Toolkit had to come to an end, as I was constantly battling performance issues. Considering that a rapid feedback loop is one of the big selling points of GT, it was a big problem that I would experience noticeable lag whilst typing text. Although, the team behind GT has since improved its performance.
Another concern I had was that the Pharo VM is single-threaded — you cannot utilise additional platform threads without booting up additional VMs, which seems inefficient.
As for the Smalltalk-style language, I ultimately decided that I still prefer Clojure’s notation. Especially when combined with macros, the Lisp-like notation is more powerful and flexible. In Smalltalk’s model, everything is an object, but sometimes this way of thinking feels forced. Consider this:
1 + 2 . “send the message + to 1 with argument 2”
2 + 1 . “send the message + to 2 with argument 1”
In Smalltalk, every operation needs a single object to receive a message, even when it doesn’t make sense to single out a particular operand. This Lisp expression feels a lot better to me:
(+ 1 2)
Project Chic
While not as dynamic as Pharo/Smalltalk, Clojure (based on the Java Virtual Machine) is sufficiently dynamic for my needs, whilst being able to easily outperform Pharo. That’s why my next endeavour strived to bring Glamorous Toolkit to Clojure.
I gave this project the codename of “chic,” because it is a synonym of “glamorous” and it is short (thus making the Clojure namespace names short).
Physics-Based Dependency Graph Visualisation

One of the greatest difficulties I face when building Clojure programs in an explorative way is namespace organisation — in which namespace should a function go? This can become a problem as the program grows, and the code gets more difficult to manage. Refactorings can be done, but they are inconvenient.
I thought it would be useful to have a visualisation of the namespace dependency graph. But I didn’t want to simply generate a static image—other tools already do that—rather, I wanted a live, interactive view into the system.
At this time, HumbleUI was becoming somewhat usable. HumbleUI is an exciting new cross-platform UI toolkit for Clojure, spearheaded by Nikita Prokopov, providing a declarative API around Skia and JWM. I couldn’t help but try it out.
As for the visual representation, I needed to figure out how to arrange the namespace nodes. My solution was to let the computer do this for me, by turning the visualisation into a physics simulation. Take a look:
The nodes are connected by lines that represent a dependency specified in the :require block. A colour gradient indicates the direction of this dependency. What’s special is that these lines act like springs that provide tension. In addition, each node is treated like a similarly charged particle, such that they repel each other.
The final ingredient is to add a variable vertical force on each node that arranges the namespaces such that the higher-up namespaces depend on the ones below. Then, by tuning a selection of parameters, one can achieve a useful, understandable arrangement of nodes.
Interestingly, there is no perfect configuration of parameters. I found that increasing the attractive force to bring all the nodes together, then relaxing it, usually gives a good rearrangement of nodes. Some nodes may also need to be manually dragged into place.
One of the most notable takeaways from this experiment is how it feels: you provide input and the program reacts, and because it’s running a simulation it can react in very complex ways. Thus, the human is able to have a live conversation with the computer through an iterative process of instant two-way feedback.
You can view the source here and more information here.
While not perfect, I consider the dependency graph viewer to be a successful proof of concept. But I wasn’t going to stop there; I wanted to be free of the filesystem, and for that, I would have to implement some sort of Clojure IDE.
Other Experiments
The humbleui-explorations repository contains an assortment of tools that I’ve made a small start on. As well as the dependency graph viewer, these include:
Error boundaries that show an image of the canvas before the error (to make UI development less painful and debugging easier).
Stacktrace viewer where you can expand the frames to see the source of the relevant function and the line of the call site. In the case of a StackOverflowError, the repeated frames are helpfully collapsed.
Basic vim-like editor.
Clojure var browser (but the source editor is broken).
Basic file browser with delete function.
Partially implemented structural Clojure editor (visually broken on high-DPI displays).
An object inspector like the one seen in Glamorous Toolkit.
Quantum circuit simulation.
Some partially implemented stuff for catching exceptions (see the status bar) and suspending/restarting threads that run into these exceptions.
Structural Source Code Editor
One of the aforementioned experiments involved starting work on an editor for Clojure code that operates directly on the AST. This is because text editing is just not optimal. Yes, it provides lots of flexibility and makes implementing a language so much easier.
But what’s the cost?
The cost is that people argue over tabs vs spaces, four-column indents vs two-column indents, and whether statements should be terminated by semicolons. This is ridiculous. This is all incidental complexity that could all be avoided!
A structural editor could enforce correct syntax, whilst giving you so much more power. With the underlying data representation abstracted away, people could view the same code in different ways depending on their preference or whatever is most convenient. That is to say, the visualisation of source code could be decoupled from its structure.
For example, Clojure developers may choose to align their bindings like this:
(let [x 420
the-beans (get-beans x)
salad (with-sauce the-beans)] …)
The problem is that this decision gets encoded in the source code, which gets committed to git, and everyone is forced to work with it. What if I don’t like this style? Instead of being baked into the source code, this alignment should be a result of how your editor chooses to represent the raw AST, such that the presentation of the code is automatic and effortless. Something like this should be impossible:
(let [x 420
sad-beans (get-beans x)
salad (with-sauce sad-beans)] …)
Furthermore, the horizontal alignment of source code depends on a monospaced font. It allows this to work:
(+ 1000 2000 3000 (/ numerator
denominator))
…without looking like this:
(+ 1000 2000 3000 (/ numerator
denominator))
What a shame — if the editor could automatically determine the indent level based on the AST and not the number of spaces in a text file, we could start using a proportionally-spaced font like Input Sans, and our code would be so much more pleasing to the eye.
Whitespace is just one way the same code could be viewed differently. What other alternative representations might be useful? That’s up to your imagination, though, I will volunteer one suggestion: alternative names. Consider the following lines of code to be equivalent:
(com.crypticbutter.knife/spread-butter)
(knife/spread-butter)
(spread-butter)
(spread)
Depending on the context, one of these particular forms may be more useful than the others. You may want to toggle the verbosity of names on the fly with a keybinding, perhaps.
Another advantage of direct AST editing is that the editor has a much better understanding of the code as you manipulate it. No need to parse a text file after each modification. This will be useful for providing suggestions, warnings, and code actions.
The possibilities are endless: drag and drop of expressions, collapsing/expanding expressions, safe copy & paste, fine-grained version control system, and so on.
Remarks on Community
My initial, messy, under-baked work on Project Chic attracted an abnormal amount of attention from people on the social interwebs. For me, this is reassuring, as it highlights that there are people who are indeed interested in better tools to aid understanding. It is also wonderful to see others working on tools to bring software development closer to what it should be — see Nextjournal’s clerk, for example.
I should also mention some other handy data visualisation tools for Clojure:
As the end of April approached, I once again had to drop what I was doing as the Easter term began.
Visual Display Brightness Control
After putting up with a single 24-inch 1080p display for eight years, I decided—partially influenced by this blog post—to obtain a basic 27-inch 4K monitor. The improvement in picture quality and screen space is substantial, and now I can’t help but notice just how incredibly blurry the 1080p monitor is!
Anyway, I tend to change the display brightness rather frequently as the ambient light changes throughout the day, and this becomes unacceptably inconvenient when managing two monitors. It also doesn’t help that one monitor requires four (slow) button presses to access the brightness setting.
What’s the solution? DDC/CI of course. The twist is that I wanted to create an intuitive, visual tool for changing the monitor brightnesses without thinking too much. Instead of a series of identical sliders, I wanted a spatial representation of the configuration of monitors, so that locating a monitor’s corresponding brightness slider becomes effortless.
A video demonstration of this tool can be found below:
Note that this tool is very crudely implemented here. It takes the easy path and relies on the ddcctl command-line utility for macOS.
Part 3: Going Deeper Into UI Programming
It was late June and I wanted to do something useful over the summer, so I continued to pour more code into Project Chic.
It began rather innocently: developing several UI controls on top of Skija and JWM, such as a button, a checkbox, and a colour picker (except you can’t pick a colour).
I began work on a pop-up multi-select combo menu, which involved submitting a small patch to JWM. Ultimately, I determined it was not the best use of my time when there are other controls that are easier to implement and get the job done.
By contrast, I did make good progress on a basic textbox implementation, with most of the functions and keybindings you would expect, cursor selection included. In fact, I made a special effort to make the text selection highlighting particularly beautiful:

Having attempted multiple textbox implementations, I have come to discover how much of the feel of the textbox is a result of the I-beam mouse cursor. If the cursor remains as an arrow, it doesn’t feel quite right.
Since it is still early days, I had to submit another patch to JWM to get the cursor working properly. Fun fact: these JWM patches are the only times that I have written Objective-C code, but Objective-C features Smalltalk-style messaging syntax, so I felt a bit closer to home.
Experiments Developing UI Languages
During the development of my dependency graph viewer, I stumbled upon performance issues stemming from the declarative model of HumbleUI. I was able to resolve these, but it required more careful thinking about how I write the UI components in order to minimise the work being done in each frame.
Nevertheless, it got me thinking about alternative ways of expressing a graphical user interface. The main tool you have in HumbleUI is the dynamic macro, which allows you to bind locals to values just like a let form. For every frame, each of these bindings is computed and then compared with the previous values. If a binding has changed, the UI component is recomputed.
This design requires some discipline since you want to ensure that the expressions that compute the values of the dynamic bindings are cheap. So then I thought, why not figure out the individual dependencies of a component, and propagate changes throughout a dependency graph when a dependency gets modified?
Coral UI Toolkit, 1988
Returning to the idea that many good ideas have already been published, I began by searching the web for UI toolkit models that have been tried before. Current UI toolkits are interesting to look at, as well as research papers.
The most interesting paper I found is this:
A User Interface Toolkit Based on Graphical Objects and Constraints, Pedro A. Szekely and Brad A. Myers, 1988.
The paper describes Coral, a UI toolkit implemented in Common Lisp, which allows interactive graphical interfaces to be expressed declaratively in a constraint-based way. When writing code for GUIs, I frequently think back to the design of Coral—it has been a lasting inspiration.
In Coral, UI components depend on “active values”. When an active value is modified in any way, only the dependent components will be updated.
User input is handled by objects called “interactors,” which, to me, is one of the most fascinating concepts introduced by Coral. The reason I like this idea is that interactors are decoupled from graphical components, which makes sense; in a typical GUI, the graphical components outnumber the distinct interactive regions. Consider this pseudocode for a button:
(clickable {:on-click …}
(border-fill {…}
(background-fill {…}
(horizontal-align {…}
(vertical-align {…}
(text-label “Click me”)))))The above component is a composition of five simple graphical components, but only one interactive component (clickable). It feels wrong that these concepts should be mixed together as though they are the same thing. HumbleUI is one toolkit that does this, since every HumbleUI component must handle events propagated down the UI tree.
Alas, the aforementioned Coral paper does not detail its interactor system, referring to a “future paper” that goes deeper into interactors and active values. Either this paper has escaped my search or it has never been published. (If you know where I can find it please let me know!)
chic.ui.ui3
My latest iteration of a UI toolkit is lazily named ui3. Main source file here. What follows is an example of a component plucked straight out of my experimental, unpolished codebase (source file here). There’s no need to understand it in detail—it’s the general structure that is important.
(ui3/deffnlet-widget
(fn ui-icon-and-label
[centre-y width->xbounds height text-width
textblob text-paint cap-height wh->icon-image]
(let [baseline-y (+ centre-y (/ cap-height 2))
icon-length (min height (* 1.2 cap-height))
icon-image ^Image (wh->icon-image icon-length icon-length)
icon-rx (/ (- height icon-length) 2)
text-rx (+ icon-rx (* util/phi icon-length))
xbounds (width->xbounds (+ text-rx text-width))
icon-image-rect
(let [iheight (.getHeight icon-image)
iwidth (.getWidth icon-image)]
(Rect/makeXYWH (+ (:x xbounds) icon-rx)
(- centre-y (/ iheight 2))
iwidth iheight))]
{:draw
(fn [cnv]
(.drawImageRect cnv icon-image icon-image-rect)
(.drawTextBlob cnv textblob (+ (:x xbounds) text-rx)
baseline-y text-paint))})))I chose an API that looks like normal Clojure but does not do as you would expect. The deffnlet-widget is actually a macro that rewrites the code to something completely different; the API was chosen so that I could still leverage clojure-lsp/clj-kondo with no extra effort, and without littering my view with unresolved-symbol errors.
This is how the API works:
The declared parameters (inputs) are appended to the parameters of a
drawmethod.The bindings of the
letform correspond to fields on the component object, where the initialising expression may depend on the component’s inputs or prior bindings/fields.For each frame, any fields are updated if their dependencies have changed, followed by the execution of the main draw function.
By default, a field is considered to be modified if any of its dependencies have been modified.
If the statically-determined type of a field implements
AutoCloseable, the object at the field is automatically closed when the component is closed.
The code in the draw function at the bottom will be executed every frame, so it is usually best to do minimal work there and use the fields to cache data.
But how does it know when dependencies have been changed? These are tracked using integers whose bits determined whether a particular input or field has since been changed. I refer to these as an input/field change mask.
This means each component relies on its parent to give it a number that indicates which of the inputs have changed. Here is another unpolished example that makes use of the previously shown component:
(ui3/deffnlet-widget
(fn ui-icon-and-label-apt
[idx filename cap-height item-height content-y
widthch->xbounds text-paint font]
(let [[textblob text-width]
(let [textline (uifont/shape-line-default font filename)]
[(.getTextBlob textline) (.getWidth textline)])
*prev-width (volatile! 0)
cmpt (ui3/new-cmpt ui-icon-and-label)]
{:draw
(fn [cnv]
(ui3/draw-cmpt
cmpt cnv
{:centre-y (+ content-y (* (+ 0.5 idx) item-height))
:text-width text-width
:width->xbounds (fn -width->xbounds [width]
(let [prev @*prev-width]
(vreset! *prev-width width)
(widthch->xbounds prev width)))
:height item-height
:textblob textblob
:text-paint text-paint
:cap-height cap-height
:wh->icon-image
(fn [^long w ^long h]
;; putting this dead code here as a workaround so that
;; this input is a dependency of widthch->xbounds
widthch->xbounds
(let [w (unchecked-int w)
h (unchecked-int h)]
(with-open [surface (Surface/makeRasterN32Premul w h)]
(let [dom (with-open [data (maticons/svg-data "description" "outlined" "24px")]
(SVGDOM. data))
root (.getRoot ^SVGDOM dom)]
(.setWidth root (SVGLength. w))
(.setHeight root (SVGLength. h))
(.render ^SVGDOM dom (.getCanvas surface))
(.makeImageSnapshot surface)))))}))})))The main thing to note is that a special draw-cmpt macro must be used in the draw function. This macro will determine the dependencies of the inputs expressed in the map, and generate code that calculates the input change mask.
In addition to change-masks, fields may have different update strategies. Fields with no dependencies are computed when the component is constructed. If the “field” is unused, then there is actually no field to store the result of the corresponding expression. Also, metadata may be used to force the field to be recomputed for each frame and to use an equality check to determine whether the field has been modified. A binding such as the following is equivalent to a binding in the dynamic macro of HumbleUI:
[^:always ^:diff= mouse-pos @mouse-pos-mut]
Here, @mouse-pos-mut is recomputed each frame, but updates are only propagated to the dependencies of mouse-pos if the new value is not equal (via Clojure’s =) to the previous value.
Each component is essentially an object that implements a specific JVM interface defining a draw method with parameters [canvas input-change-mask …inputs]. The interface is what parents depend on, and is specific to the number of parameters and their types. Therefore, you may re-evaluate a child component and have the parents see the update as long as the signature of the child component’s inputs is unchanged (the existing interface will be used). Otherwise, if you modify the interface of a child component, you probably would need to modify the parents anyway.
Drawbacks
The model that I have just described is definitely not perfect, and the limited quantity of code that I have written with it is full of workarounds, particularly to handle cases when the size of the parent depends on the size of the child. More work is needed to improve convenience and to ensure all cases are handled well. One thing I have considered is adding a recompute method (similar to HumbleUI’s -measure method) to components that get executed before draw, providing a gap in which the parent can do stuff that depends on the child’s state. Although, I wanted to keep the fundamental design as simple as possible.
The code also gets very verbose, because components tend to have a large number of inputs, and these are provided individually by each parent. By contrast, HumbleUI avoids this problem by standardising the use of a single context map parameter for each component.
While those issues are inconvenient, by far the biggest problem with my approach is all the macro magic. It makes components convenient to write and easy enough to understand, but only when the macros work. Debugging the macro implementations was a nightmare due to their complexity, and the fact that an enormous amount of code gets generated.
Unlike innocent macros, my evil macros employed tools.analyzer.jvm (for determining types and dependencies), as well as the insn library (for JVM bytecode generation). The result is that component definitions may take hundreds of milliseconds to evaluate, presumably due to slow macroexpansion.
As an aside, I also used tools.analyser.jvm in a few utility macros, but I would have rather not used it because it does work (e.g. type inference) that the Clojure compiler already does. What I was really looking for was a way of extending the compiler, which foreshadows my later work.
Interactors
You might have noticed that ui3 only deals with graphical components, and provides nothing for handling user input or other events. This is separation is by design. For my experiments, I whipped up a basic system of “interactors.” I named this after interactors in Coral, but obviously, the research paper provided few details so I used my own interpretation.
In my model, each interactor is tied to a rectangular region of the window. This region is used to determine whether the interactor should receive mouse events.
An interactor might not handle an event, causing it to be passed to the next suitable interactor.
Each interactor is registered with an “interactor manager” which, not only routes events, but keeps track of which interactor is focused. Focused interactors receive keyboard events.
UI components may manage interactors, update their regions, and respond to events via callbacks.
Note that my system of interactors has not been implemented completely, nor has it been used enough, to be in any way refined. The small existing implementation is here.
Part 4: Yet Another JVM Language
As I have alluded to earlier, I have wanted more control over the compilation of Clojure code, leading me down the roads of using things like insn and tools.analyser. Also, I was dissatisfied by the reality that, if you needed utmost performance, you had to rewrite your program or library (or parts thereof) in Java. I did not like that solution as it is substantially less ergonomic and dynamic.
Wouldn’t it be great if all the code used the same language, rather than dealing with an artificial divide between two very different languages?
Furthermore, Clojure is a heavy library. Thus, even the smallest Clojure program pays the cost of loading the core library. Why not have the essence of the language without the entire core library?
Well, the more Clojure I wrote, the more I became familiar with the Clojure source code, and the more I learned about how the JVM worked. At one point, I wanted to fork Clojure to experiment with alternative bytecode generation—a task that made me more comfortable with JVM bytecode and ASM.
Eventually, I gave in to the nuclear option: implement yet another programming language that runs on the JVM.
This would give me full control, eliminating the pains of working around the restrictions of Clojure, whilst opening up opportunities to experiment with new ways of expressing and organising source code. Additionally, I would be able to take advantage of the dynamic JVM features added since JDK 8.
Why the Java Virtual Machine?
If you’re going to go to the effort of creating a programming language, you would want to make sure you’re building it on solid foundations. Here, I’ll share why I’m willing to invest my time and effort into the JVM and OpenJDK:
It is highly dynamic, allowing code to be loaded on the fly.
The developers are committed to a reasonable amount of backwards compatibility.
Development is trending in a positive direction, with projects (such as Valhalla, Loom, Panama, etc.) that will make the JVM more performant and more friendly to alternative JVM languages.
Specific features are supported that strongly benefit dynamic programs.
It’s one of the most popular platforms, resulting in a vast range of libraries.
The JVM goes all the way back to 1994 and has proven to be reliable.
It’s customisable via a plethora of JVM options.
Brief Introduction to JVM Languages
The JVM (Java Virtual Machine) is a program described by its specification. There are many implementations of the JVM, each with different characteristics.
The JVM users classloaders to load code from class definitions expressed as bytecode. Class files contain class bytecode. For more information about classloaders and the classpath, see: The Classpath Is a Lie.
JVM languages such as Clojure and Java compile source code into class bytecode. A great thing about the JVM is that while it is developed alongside Java, it is not strongly coupled to Java and alternative languages are warmly welcomed.
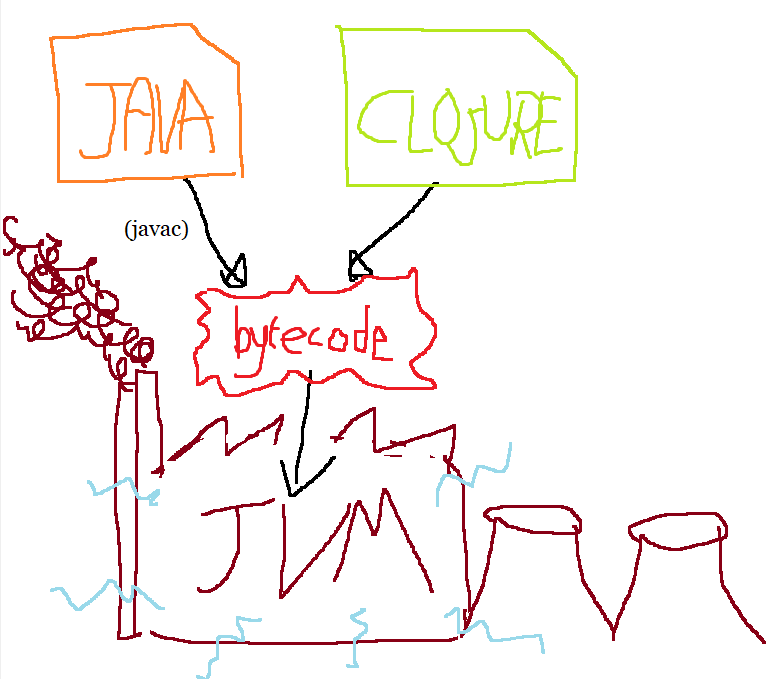
Each function in Clojure is compiled into its own class and any captured locals are loaded into fields of the function object created at the call site.
The JVM abstracts over the platform’s architecture by providing its own instruction set of over 200 instructions. Each instruction is represented by a byte. Instructions only occur in method bodies of classes.
ASM is the library used by Clojure and others for generating bytecode.
Introducing Project Squawk
Squawk is the name I gave to the programming language I began developing. It is currently implemented in Clojure and the source is found here.
Squawk is a Clojure-like Lisp dialect, but lacks many of the features that make Clojure convenient. At the moment, it is a minimum viable programming language that allows programming in a similar way to Java.
Since the JVM is object-oriented, it was easiest to start by using Squawk as a convenient Java-like bytecode generation tool. By contrast, Clojure aims to abstract over the JVM’s object-oriented programming model, consequently restricting how much control you have over the generated classes.
Nothing in this language is set in stone, though here is an incomplete description of how to program in the current language:
;; method call
(jc Class method ...args)
(.method obj ...args)
;; call method on superclass
(^Super .method obj ...args)
;; field access (I'm not so keen on this notation myself)
(jf Class field)
(jfi obj :field)
;; New objects
(nw Class ...ctor-args)
(na Class length) ;; new array
(cast Class obj) ;; same as Java's cast
;; Conditionals on boolean tests
(when test ...body)
(if test then else)
(and ...tests)
(or ...tests)
(not test)
(case-enum enum-obj, VALUE1 then1, VALUE2 then2, fallback)
;; Tests
(identical? obj1 obj2) ;; same as == in Java
(= a b) ;; same as == in Java
(nil? obj)
(instance? Class obj)
;; Loop (like Clojure)
(loop [binding init ...]
...body)
(recur ...values)
;; Local bindings examples
(let ...binding-pairs child)
(let
num1 1
another-num (+ 5 num1)
(- another-num num1))
(do
(=: x 5) ;; the binding 'leaks'
(+ 3 x))
(when (not (nil? (=: thing (.getThing obj))))
(.use thing))
;; Exceptions
(try ...body
(catch ExceptionClass binding ...body)
(catch [Class1 Class2 ...] ;; union of classes
binding ...body)
(finally ...body))
;; Number literals support more types than Clojure, e.g.
1f ;; float
1d ;; double
1L ;; long
1i ;; int
1b ;; byte
;; Persistent collection literals
[1 2 3] ;; vector (List)
{:x 1 :y 2} ;; map
;; Anonymous classes, capturing locals
(reify SuperOrInterface
...Interfaces
(method-name [self ...args] ...body))
;; Class definition example
(defclass MyClass
:super SuperClass
:interfaces Iface1 Iface2
[field1 ^String field2 ^int field3 ...]
;; :priv, :pub and :pub-pkg metadata can be used
;; to control accessibility of a class member
(def a-static-field 42)
(def ^:priv a-static-field-private 43)
;; Return type indicated by type meta on param vector
(defi instance-method ^void [self ...args] ...body)
(defn static-method [...args] ...body)
;; Constructor
(init [self ...args]
(init-super self ...args)
...)
;; If constructor not specified and a field vector is
;; provided, a positional constructor will be generated
;; like Clojure's deftype would
;; For convenience, in method bodies, "Self" is an alias
;; for the method's class.
)
;; Interface definition example
(defclass MyInterface
:tag [:interface]
(defabstract method [...args]))
As the goal of the language is to let you get closer to the JVM, it is easier to write code that operates on primitives. Clojure, in contrast, is liberal with its use of boxing and makes various primitive operations difficult or impossible. So, arithmetic in Squawk is equivalent to arithmetic in Java, with its speed and risks of overflow. This also means you need to pay more attention to types.
Types can be specified in a similar way to Clojure, with metadata, except type metadata is not a type hint—because the compiler takes the specified type as a certainty.
In Clojure, a method or class of the name a->b! gets munged into the name a__GT_b_BANG_. You may think this is due to Java’s restriction on characters in method and class names, but a JVM language does not need to play by Java’s rules—it only needs to follow the JVM’s rules. It turns out that the JVM is much more relaxed than Java, permitting class and method names to contain almost any Unicode character (there are a few constraints detailed in the specification). As a result, Squawk allows method names with characters such as - and ! in the bytecode, which makes stack traces more readable.
As for persistent collections, I decided to use the bifurcan library, which claims to have good performance characteristics.
For each method invocation, the compiler uses an algorithm that approximates that in the Java Language Specification to determine which of the method overloads should be used, based on the inferred types.
Squawk also uses basic casting and (un)boxing rules similar to Java. Despite that, you still currently have to do a lot more manual casting and conversion than in Clojure, especially since generics are not supported.
Macros are currently not supported; everything is a special form 🙃.
Dynamic Classes
At the moment, you may be thinking that all I have described is a subset of Java in the form of a Lisp dialect, and that’s about true. However, Squawk uses a few tricks that leverage the dynamic features of the JVM in order to make programming more pleasant than Java.
Normally, when a class is loaded, all of its references to other classes are resolved and become fixed. This means if you modify and reload one class, the changes will not be reflected in the dependent classes. (The JVM does not allow arbitrary modification to classes—the only option is to create a new class.)
Obviously, we want to be able to dynamically change parts of the program at runtime and discard the previous version of the code. Clojure achieves its dynamism by dereferencing vars at each call site, but what if you want dynamism with plain, Java-like code?
This can be done with the invokedynamic bytecode instruction. This enables dynamic linking of classes via a custom bootstrap method and makes it possible to switch out the call site with an updated call site for the updated class. Moreover, unlike Clojure, this strategy can (in theory) be better optimised by the JVM, as you only really pay for the dynamism once.
Another benefit of this approach is that it would be very easy to turn it off, and generate static code (like Java would) for production.
Squawk also leverages “dynamic constants,” introduced in JDK 9. This allows arbitrary objects such as keywords to be placed in the class’s constant pool.
Here’s a REPL example of reloading a class:
(defclass Alpha
(defn print []
(.println (jf System out) 1)))
(defclass Beta
(defn print []
(jc Alpha print)))
(jc Beta print)
out: 1
;; re-evaluate modified class
;; the old Alpha class becomes invalidated
(defclass Alpha
(defn print []
(.println (jf System out) 2)))
;; Beta class links to the new Alpha class
(jc Beta print)
out: 2In order to achieve hot-class-swapping, one must work around the limitations of the JVM’s classloader system. Since classes can only be garbage collected when their classloader is no longer reachable, it makes sense to create a new classloader per class (this is what Clojure does) rather than using a single class loader. Thus, individual classes can be GC’d without unrelated classes keeping the classloader alive.
Luckily, there might be a slightly better way: JDK 15 introduced the concept of a “hidden class.” These should be much more lightweight and faster to load. As they are not tied to a classloader, they may be garbage collected individually. This is how Squawk loads “dynamic classes.”
Towards a Squawk IDE
The first and only significant example of Squawk is another text editor implementation (source here). Going a step beyond my previous implementations, this editor actually has the ability to save files and switch between them.

While basic at the moment, the intent is to develop it into a tool that makes it convenient to write and navigate Squawk source code without dealing with files.
Of course, the very long-term goal is a structural editor like what I have discussed earlier, but the short-term goal is to make wean the developer off the filesystem and instead use links and backlinks to navigate small portions of source code.

The above demonstration shows how I can quickly navigate to another file with minimal brain-power, by selecting a relative path and pressing ctrl/cmd+G. If the file does not exist, it is created. On the left-hand side is an ordered list of recently visited files so that you can trace back your steps.
I hope you can see beyond this barely-functional proof-of-concept and appreciate the greater vision: small units of source code connected together in a graph database—the Roam Research of programming environments.
Ideally, each unit of source code would have a unique, immutable id that is decoupled from any name, because good names are hard to come up with. Also, changing a name can be a painful and unreliable process (especially in Clojure where namespace names correspond to file paths). Why trap the developer into deciding on a name before any code can be written?
The Unison programming language has an interesting system of managing code: each piece of code is represented and identified by its hash.
Instead of enforcing a brittle hierarchical structure, I want to make it a frictionless process for code to start life as some rough expressions on the daily notepad, and then grow and evolve over time as it forms connections to other nodes in the code graph.
More Ideas for Squawk
The syntax for field access in Squawk is inconvenient. I couldn’t use the same style as Clojure, like (.-value obj), seeing that -value is a valid method name. Perhaps (.'value obj), or even allow keyword lookups on eligible objects to access their fields, like (:value obj).
At the moment, Squawk does not do any constant propagation, meaning the code (+ 1 2) results in a program that always performs the addition, even though the result can be determined at compile-time. Something like what Zig’s comptime keyword provides is also a worthy goal, which could enable an elegant way of writing generic functions and reduce the need for macros.
Stack trace frames can provide line numbers, but that’s not so useful when there may be many expressions on a single line. Unfortunately, this is the most granularity that the JVM provides. To alleviate this problem, one might consider using “line numbers” to correspond instead to an expression number. Then, the stack trace can be processed by some function that maps the fake line numbers to a specific location in the code.
Speaking of debugging, the Java Platform Debugger Architecture (JPDA) could be used to give you superpowers. The power it grants is nowhere close to that of a Smalltalk system, however, it could still be useful for things like interactively recovering from an exception.
While I have played around with the debug interface a bit in Project Chic, I have not used it much and would rather not rely on it. The JPDA has a few interfaces, including the Tools Interface (JVM TI) which is a native API, and the Java Debug Interface (JDI) which is a limited Java API and located in sun packages. Also, debugging needs to be explicitly enabled via an option flag. Sometimes, if you are like me and you don’t know what you are doing, the debug interface can lead you into bizarre problems such as ObjectCollectedException.
About The chic Repository
The bulk of the work that I have described in this article can be found in this source code repository. Since it serves as a code playground, it is full of all sorts of unfinished, unpolished mini-projects. In addition, notes to myself are scattered all over the codebase. If you decide you want to run the project, remember that in various places the code depends on certain fonts and references file paths specific to the machine I was working on. It is guaranteed to not work fully. After all, it’s an experimental playground.
Conclusion
This article covered an assortment of the things I have learned from my programming adventures over the course of the last year. It began by describing the tragic state of software, followed by explorations of a few lower-level languages. Then, I showed several visualisation tools and my own attempts at designing a UI toolkit. Finally, I shared my work on a new experimental JVM language.
If there is one thing you take away from this article, it should be that software and software development has the potential to be a lot better than it is currently. Don’t give in to the JavaScript nightmare! And let’s build software for humans, not machines.
I have found this article to be extremely thought provoking and informative! Though I have yet to build a knowledge base as in-depth as one necessary to construct an article on topics such as the development of a language built onto the Java Virtual Machine to navigate around the constrains of another language, I still found everything within this article to be intriguing, and I will be sure to do some of my own research into the topics covered!
I did however find myself nodding in agreement with the (in my opinion) valid arguments against JavaScript, in fact I have made it a personal aim to utilise the language when engaged with web development as little as possible purely out of some tribal spite I have for it.
Though I have a question. Just out of curiosity, I read that you have tried languages like Rust (which I personally see the appeal with, especially now that it is being included in the development of the Linux kernel) but I haven't read about your experience with languages such as C or C++? Are these languages not capable of what you want to achieve?
Thanks in advance, I have thoroughly enjoyed reading this article and I hope to learn from it!
Genuinely curious, can you elaborate on the 'Javascript nightmare!' stuff?