
Compilers, Editors, Typefaces and More From the Ground Up
My pursuit to reimagine developer tooling and implement 2D graphical applications from an almost entirely blank slate.

In the four years since my previous progress-update article, I have been working on a series of experimental projects and learning about the low-level fundamentals of software—down to the finicky particulars of things like text rendering and x86 machine code generation.
Here is a brief, incomplete listing of these projects:
(Late 2022) Structural editor for Clojure, with code stored non-hierarchically in a database. (Early prototyping phase.)
(First half of 2023) Compiler, structural editor and debugger for a custom language with a bytecode interpreter and x64 machine code backend. The language is imperative, strongly typed and assumes manual memory management, but has a Clojure-like syntax.
(Mid 2023) ButteryTaskbar2: a reimplementation of my original utility for Windows, improved to be simpler and more efficient.
Basic GPU-powered 2D rendering via Direct3D 12.
OLKCH colour picker.
(Second half of 2023) Two different attempts at a structural editor for the Jai programming language.
A simple alternative language to Markdown.
A tool for viewing and editing notes using a graph-based structure similar to Roam Research. Notes are written in my Markdown alternative.
Static website generator using my Markdown alternative for webpage content.
A programmatic generator for my six-segment logo, using TinyVG for rendering.
XML parser.
Implementation of Myer’s and Dijkstra’s algorithms for diffing a source code AST, together with a fun (but vitally useful) visualisation of the diffing algorithm.
(First half of 2024) A text editor for code, featuring syntax highlighting, Tree-sitter integration, adjustable panels, Regular Expression text search, modal editing, macros and undo history.
libgrapheme ported to Jai.
(Second half of 2024) Compiler and bytecode interpreter for a custom modern C-like language.
(Late 2024) A simple bespoke tool for tracking deadlines and reminders. Uses SQLite and a minimal browser-based UI. I continue to use this tool to this day.
Win32 API bindings generator, which converts the JSON data from win32json into a serialised binary form, which is then selectively converted into code declarations.
(2025 onwards) A blank-slate code repository with a bespoke build system and custom implementations of core libraries for purposes like memory management, file system access, hash tables, etc. This is the basis of all projects that follow.
(Early 2025) A utility to provide various comforts on Windows, including navigation key bindings, synchronised display brightness control, and sticky window edges (like macOS).
A more ergonomic and flexible alternative to JSON.
Basic SIMD-accelerated software renderer written in assembly for AVX2.
(Mid 2025) Initial prototyping work on a new design of a structural code editor, inspired by the Kyra language and editor.
Glyph rasteriser (CPU-based), capable of directly rasterising both linear and quadratic edges. Inspired by the approach in stb_truetype, but designed to be SIMD-friendly.
A new programmatically-defined quasi-proportionally-spaced typeface designed to be both legible and fast to render, by minimising vertices and preferring quadratic Bézier curves over cubics. A simple bespoke text layout system replaces the dependence on Harfbuzz.
(Late 2025) Another attempt at a UI toolkit, which includes a more powerful layout system, better support for incremental updates, and dependency analysis to optimise GPU draw calls.
Vulkan bindings generator, which sources data from the official XML-based specification.
(2026) A revised text editor, bringing together my latest work on UI systems and text rendering. It is powerful enough that I now use it as my primary code editor for my Jai-based projects. Like 4coder, it implements virtual whitespace, which greatly improves the experience of working with code indentation.
All of these projects constitute an extensive volume of research and time spent in deep thought. This article does not aim to give exhaustive coverage of all the ideas and implementation details across these four years, but merely to serve as an overview of some of the most interesting points.
Reinventing Software Development Tooling
Recurring themes in my work include compilers, innovative code editors, and novel programming language design. I feel like there is opportunity to bring substantial improvements to the development experience by reducing superfluous sources of friction, cutting out bureaucratic busywork, and tightening feedback loops. My main points of focus have been:
Structural code editors to give a more refined editing experience with more powerful and robust code intelligence and transformations.
Rethinking code organisation to make it easier to scale, manage, and adapt complex codebases. This means storing code declarations in some kind of graph database instead of a tree of files.
A more interactive debugging experience leveraging tightly integrated code introspection along with dynamic code compilation and execution.
My research in this area is still early and highly experimental, though I now have a better idea of what probably doesn’t work, and what could work.
Whilst searching for prior art, I encountered this video which is the best demonstration I’ve found of a structural editor and its benefits.
2023H1 Programming System
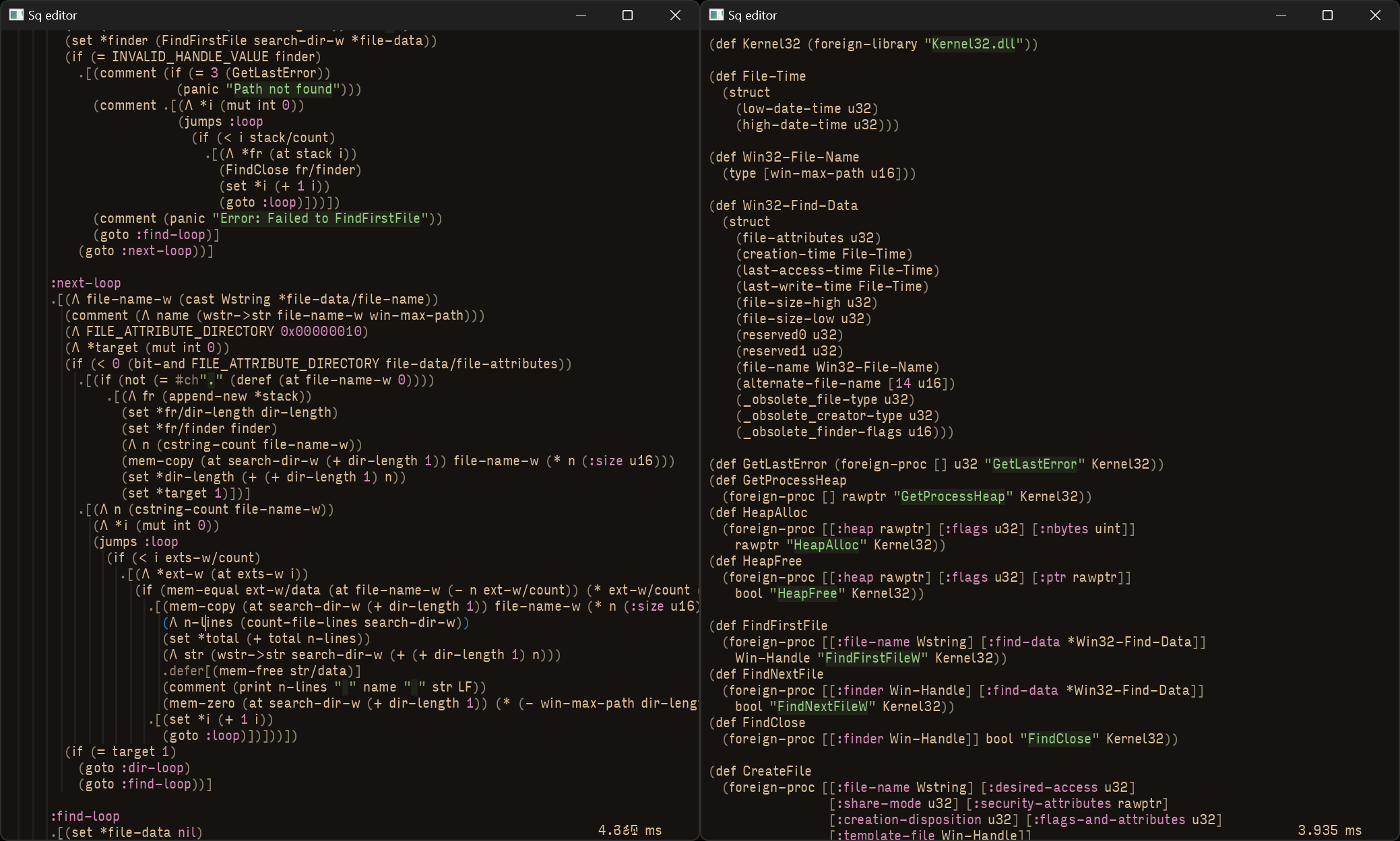
I started off by implementing a programming language with a syntax very much like Clojure, because I was most comfortable with that at the time. The simplicity of Clojure’s syntax makes it very powerful, and makes it a particularly good fit for a structural code editor.
In addition to a structural editor, this project implements a primitive compiler that emits both bytecode and (to a limited extent) x64 machine code. Initially, I implemented a tree-walking interpreter, but that was awfully slow. The bytecode interpreter was a significant improvement, but still orders of magnitude slower than machine code. The x64 backend is capable of directly generating a valid Windows executable binary without needing to depend on an assembler. The most sophisticated program I tested is a program that counts the total number of lines of all text files in a directory.
I also implemented a primitive debugger that integrates with the bytecode interpreter. Unfortunately, I do not have any images of this and now I cannot easily compile the project. This debugger had a GUI that displayed a listing of the bytecode instructions as well as the current contents of virtual registers and stack memory. You could set breakpoints, step through the program, and watch the program state change in real time.
I was initially using Skia for rendering, but later switched to doing basic software rendering with FreeType and Harfbuzz handling text rasterisation and layout. In the bytecode interpreter, I used Dyncall for dynamically calling procedures in dynamically-loaded libraries.
2023H2 Programming System
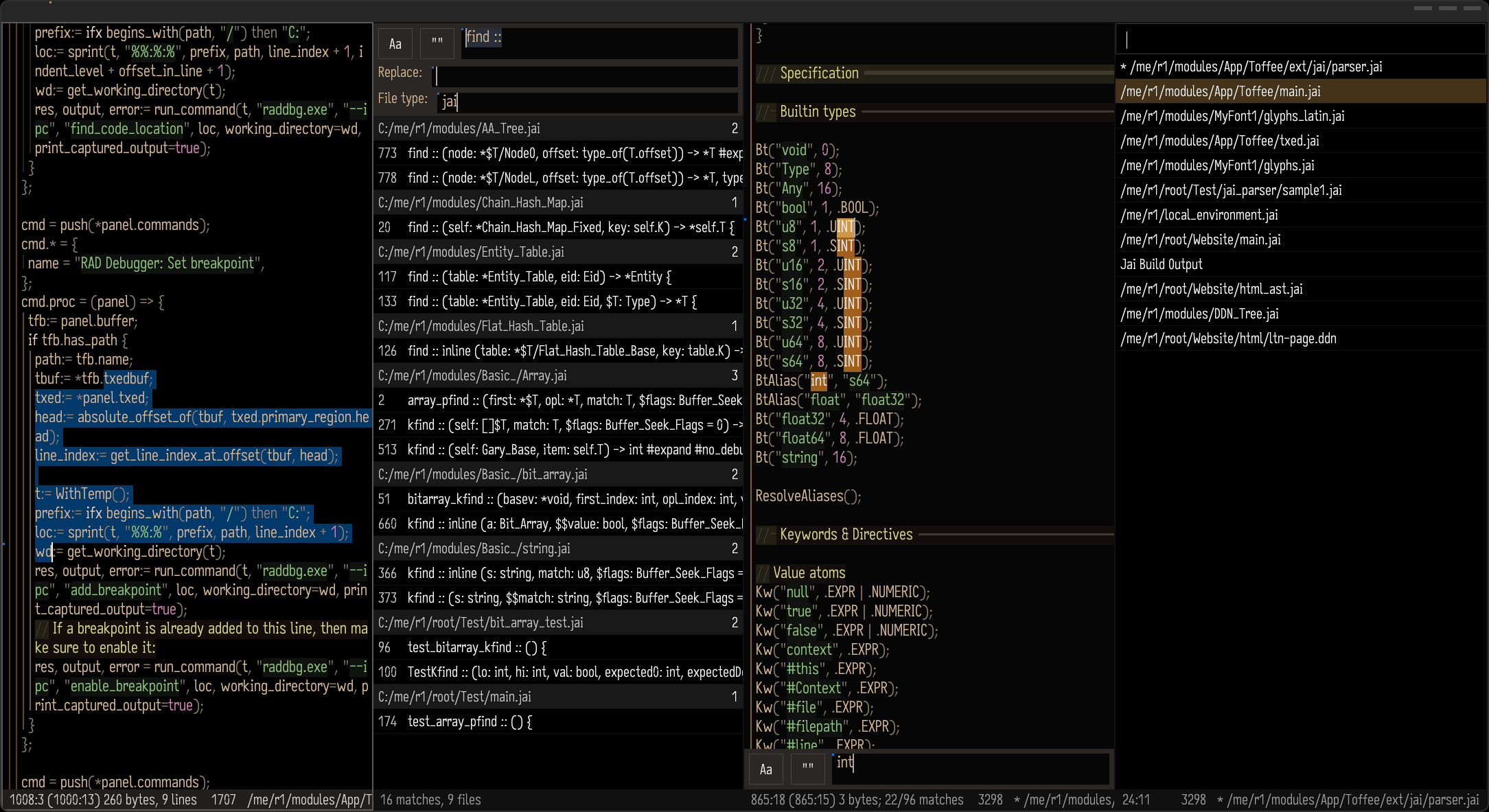
My subsequent experiments involved building structural editors for the Jai programming language. The problem with a Lisp-like syntax is that its simplicity means it can be verbose when expressing the same amount of information that a statically-typed language needs to express. In such a statically-typed language like Jai, it pays off to have more complex syntax in return for brevity.
At first, I tried an editor with four types of node: token, string, block and newline. A block corresponds to a pair of brackets—(), [] or {}—and contains a list of nodes. However, this did not feel powerful enough, so I proceeded to implement an alternative design with a more heterogeneous AST that more closely reflects what the compiler is working with. For example, declarations, binary operations, if statements and procedures are each their own distinct type of node in the editor.
The result was a fun, visually unique demonstration, but it revealed a challenge in the design space of structural editors: increasing the heterogeneity of the editor AST greatly increases complexity and makes editing operations similarly heterogeneous. In order to create nodes of a certain type, my solution was to use special key bindings, text commands, automatically converting a typed-out keyword into its corresponding type of node. This does not feel as fluid as the experience of editing a uniform array of characters in a traditional text file. Manipulating the tree becomes more difficult since it requires a larger set of more specialised operations, which imposes a greater cognitive burden.
There are also questions like:
How specialised should the editor’s AST be?
Should you be able to insert AST nodes of a certain type into a slot that is invalid for its type?
Should you be allowed to partially select the contents of a node in the same selection that contains its siblings? How should selection ranges on a tree structure work?
Having done this experiment, I am now leaning towards a structure that is more uniform, but that needs further research.
Graphics Rendering
When implementing GUIs from scratch, there is a question of how to render graphical elements to the screen (after everything is laid out). A few options:
Use a library (like Skia or Blend2D) that abstracts away all the difficult parts.
Build a CPU-based software renderer.
Use the GPU by directly interfacing with an API like OpenGL, Direct3D or Vulkan.
Initially, I was using Skia because it is very capable, cross-platform, and was familiar to me. If I recall correctly, I was having performance issues rendering text in Skia. Almost certainly, this was because I was using it wrong and probably there was a lack of glyph caching, but I took this as a good excuse to write an extremely simple software renderer and handle text myself using FreeType and Harfbuzz.
My original software renderer was slow and I needed more performance, so I looked around. For a brief moment, I used Blend2D, a 2D CPU-based graphics rasterisation library, but performance was still not satisfactory. Furthermore, Blend2D is such a large, complex project that I would rather not depend on.
In 2023, I eventually gave in to GPU rendering and spend over two weeks learning how to use Direct3D 12 to produce the most basic 2D graphics. This was some serious drudgery, but in the end I had working shaders for drawing rectangles, images and glyph runs of text. OffsetAllocator was used for managing GPU heap memory. The speed gain from GPU rendering was especially apparent in the OKLCH colour picker I made.
Later, in 2025, I explored writing a CPU-based software renderer written in x86 assembly language. Because this used AVX2 instructions and could operate on eight pixels at a time, it was much faster than my prior software rendering attempt. I experimented with an implementation that operates on 8-byte integer colour channels, and another that operates on 16-byte floating-point colour channels for better blending accuracy (using special FP16 x86 SIMD instructions). My aim with this effort was to win some simplicity and avoid having to interface with a GPU graphics API which all have significant start-up latency.
This software renderer was initially inspired by the design in Handmade Hero, which approximates gamma correction by the square and square root operations. Unfortunately, this approximation results in a very noticeable loss of accuracy and attempting to do anything more accurate is prohibitively expensive. Even without the accurate gamma correction, the software render is still much slower than the GPU. Therefore, I had to conclude that GPU was the only feasible option for performant and accurate 2D graphics, which sadly meant enduring more of the misery of working with complex graphics APIs.
Approaching the end of 2025, my faith in the Windows operating system was nearing zero. I did not want to tie myself to this rapidly decaying platform if I could avoid it. Thus, I started learning Vulkan and used it to implement a basic 2D render. Vulkan Guide helped me get set up and I used the VulkanMemoryAllocator library because apparently it’s silly not to. HowToVulkan is a newer guide that I haven’t looked at but seems promising.
Vulkan has the benefit of giving you access to the latest features in GPU technology, whereas OpenGL is antiquated and better avoided nowadays. Vulkan is not fun to work with, but that’s where the future is headed, and that’s not a decision I get to make. The bindless APIs in the newer Vulkan versions makes things easier and enables substantial simplifications such as eliminating the need for a glyph atlas.
Designing a Typeface and Text Layout System
In designing UI systems, it has become clear to me that text rendering is by far the most complex and computationally-expensive part of rendering simple 2D UIs. This is because glyphs first have to be rasterised from a vector format into a bitmap image, then a potentially very complex set of rules need to be applied to compute the positions of each glyph in a string of text.
Glyph caching helps improves performance by saving the bitmap of a glyph, but the bitmap is only valid for a specific sub-pixel offset, and glyphs can be positioned at any non-integer coordinate. If you round the glyphs to the nearest pixel boundary, the text becomes noticeably unevenly spaced.
In my prior text rendering solution, I instead rounded each glyph to the nearest 1/3-pixel boundary which reduces the visual error, but requires up to three cached bitmaps per glyph.
Another solution I tried was to instead use a word cache: split up the text into short segments (words) and rasterise each word as a single bitmap image. This means that the spacing between glyphs in a single word is perfect, at the expense of more memory spent on storing bitmaps.
But I wanted something better. Following good engineering principles, I considered my specific situation and considered—from first principles—what an optimal text rendering design would look like. Here are some of the constraints and assumptions I came with:
Support only for left-to-right scripts like Latin, Cyrillic and Greek.
Glyphs must always be pixel-aligned (so there is one bitmap per glyph with no need for sub-pixel variants).
Support for characters of various widths (not just monospaced typefaces).
Kerning is applied to each pair of graphemes, with no further context allowed.
Font size is determined by cap height which must be an integer.
No sub-pixel anti-aliasing like ClearType; it complicates colour blending, only works well in limited cases, and results in colour fringing. I would prefer using high-DPI displays so that sub-pixel anti-aliasing can be a forgotten artefact of the past.
By constraining the problem I am attempting to solve, I can search for opportunities to make the targeted solution significantly superior to general solutions like TrueType and Harfbuzz. And indeed, I concluded that I would be better off throwing out TrueType/OpenType, Harfbuzz (or equivalent) and FreeType (or equivalent).
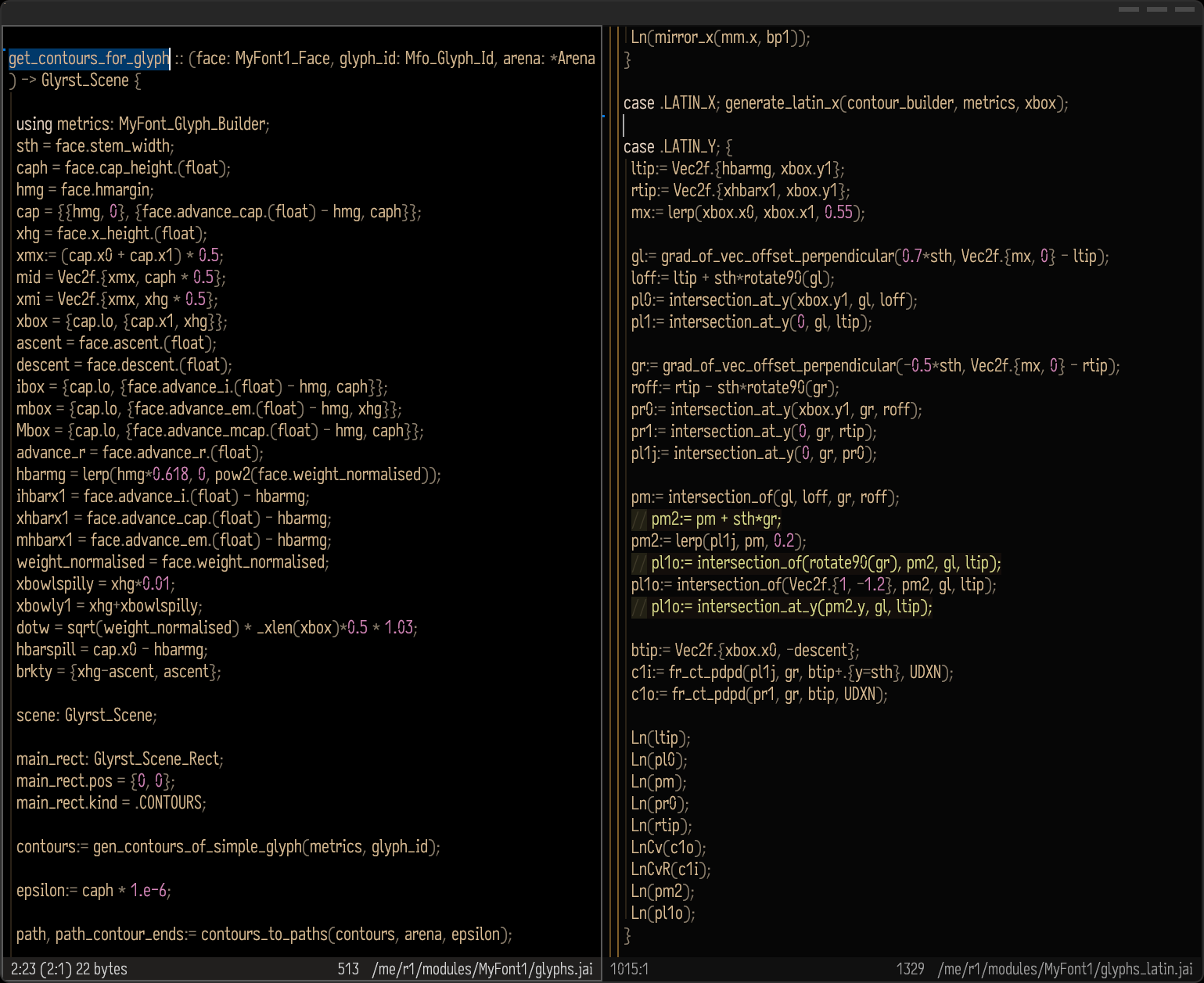
Firstly, I needed a glyph rasteriser to replace FreeType. The goal of this is to have a simple piece of code that does exactly what I need in a way I control. I learned about the mathematics of glyph rasterisation, giving careful consideration to floating-point precision limitations, and proceeded to implement a rasteriser in less than 800 lines. This rasteriser directly supports quadratic Bézier curves, unlike stb_truetype, which has to approximate such curves by a series of straight line segments.
Secondly, I needed a typeface. Since I had chosen to reject the design of TrueType, I had shut myself out of the ecosystem of pre-existing typefaces—I had to now create my own. This process took much longer than I initially anticipated, and so I spent months swimming a laborious mathematical soup of twists, turns, and dead ends.
TrueType fonts work by representing each glyph as a collection of contours, where each contour consists of segments of either quadratic Bézier curves or straight lines (which is just a degenerate case of a quadratic Bézier curve). It gets further complicated by font hinting, which requires the use of an interpreter to read TrueType bytecode instructions which make adjustments to the vertices for better alignment with the pixel boundaries at a certain font size.
I also wanted to support hinting (where the glyph shape is optimised for the pixel boundaries at a certain size) but I wanted to implement it in a simpler way. Instead of representing my typeface in a bespoke data format (something like a ttf or otf file), I decided that my typeface would be defined in executable code for maximum flexibility. With this design, the process of obtaining a set of glyph contours involves calling a function with three key parameters: the typeface, the font size, and the glyph number. The code then directly computes the optimal glyph vectors depending on the font size, without needing a complicated bytecode interpreter. It’s all just regular imperative code.
Two main principles informed the design of my typeface:
Legibility: characters should be reasonably distinct and readable, even at rather small font sizes.
Performance: there should be minimal computational cost involved in generating the glyph vectors and rasterising them. This meant that I aimed to use as few curve segments as possible, including minimising the use of cubic Bézier curves (which must be broken up into quadratics prior to rasterisation).
To make the glyphs look as good as possible, I studied quite a bit of mathematical theory as I needed to be able to generate curves that ideally maintain G2 continuity, but these curves need to be cheap to generate. For weeks, I chased after mathematical derivations in SageMath trying to find formulae for computing curves that satisfied various invariants. This turned out to be much less fruitful that I had hoped; often, the sets of equations would be too complex to solve, or no solution would exist at all. I had also taken plenty of time to check the prior research, including the work done by Raph Levien, but I wanted something as simple as possible and much of the research involved mathematical expressions that lack an analytical solution and thus are not trivial to compute (which would violate my performance constraints).
Eventually, I completed the designs for the ASCII range of characters. You may think, as I did, that the small range of ASCII characters wouldn’t take that much work to design. But I was waiting for the day that it would end, and I felt like it would never come.
Putting this all together into a text rendering system, I was definitely surprised by how well the result turned out. The text rendering system is now much simpler, and I can now comfortably use my own proportionally-spaced font in my own code editor.
From Clojure to Jai
This section presents some of my reasoning as to why my style of programming dramatically shifted away from the dynamic, functional, GC-powered land of Clojure and towards embracing a more imperative, statically-typed, systems-level kind of programming.
Clojure Is Too Slow, and Performance Matters
Having become reasonably experienced using the Clojure programming language for over two years, I repeatedly found myself running into the same insurmountable obstacle: performance. Put simply, Clojure is too inefficient for high-performance software, and the program start-up time is unacceptable. I have spent a lot of time optimising performance in Clojure programs but nothing is ever enough.
In my previous article, I discussed my attempt at building a compiler for a custom JVM-based language which aimed to be more performant, but eventually I had to face reality: the Java Virtual Machine is too slow and limiting.
There is a good reason the JVM has not taken over the world of performance-critical software (operating systems, codecs, game engines). Even in cases where performance is less critical, choosing to build your software with inefficient technology like the JVM still does a disservice to your users, since the result is often:
Less responsive and more sluggish (even for simple UIs, the slightest difference matters).
Less power efficient (especially important for laptops).
More complex (larger binary sizes, possibly requiring a separate JVM installation).
To illustrate the importance of performance, if a compiler takes two seconds to compile instead of one, the added delay further breaks the flow of development and decreases dampens one’s spirit. Billions of people use software every day, so each minor delay quickly adds up to an unfathomably great waste of human hours spent waiting for software to respond.
Performance also affects the user’s pattern of behaviour. For example, the slow file search in Windows File Explorer means that I never use that feature. If the performance of the search were much better, then superior workflows could be enabled that take advantage of that search feature. This is not merely hypothetical: nowadays, with FilePilot, I use text search to rapidly navigate the file system all the time.
A common dogma in computer programming is that you should not be optimising for performance until you know your performance requirements and bottlenecks. To a large extent that is true, but it is not an excuse for things that are slow for no good reason; these things, polluted with junk, can be made faster without sacrificing a good programming experience, and in fact the programmer’s experience will often be improved by prioritising performance and simplicity.
As soon as you choose to use something like the JVM, you have already accepted a significant performance and memory penalty. If people don’t think about performance from the beginning, we end up with a proliferation of slow software (the world we live in now). You may take steps to optimise the program (which naturally makes it more brittle), but you will always have the foundational issue of running on a suboptimal, managed VM.
Programs should be fast by default—and the language should push the programmer in the direction of something that is not horribly inefficient. At the very least, there should be a pathway to transform the program into something that makes reasonably efficient use of the hardware.
Also, if you are developing a library, you should assume highly strict performance criteria, since you do not know in which contexts your library may be used. Pouring a huge volume of effort into a fundamentally slow technology may waste the time of your users. But it will also cut off those users for whom the library is too slow, thus their time is wasted by not being able to do what they want to do without reimplementing the library features.
In the case of a desktop applications, it is imperative that they be fast and responsive, out of respect of the user. It should be normal that it be fast and responsive, without any special effort. Computers are incredibly fast—fast enough to drive interactive 3D worlds with complicated graphics—yet even simple programs struggle to meet reasonable performance expectations. Even if you do make the program feel responsive, its inefficiencies can still impact the user experience. For instance, you may consume an absurd amount of memory that reduces the user’s multitasking potential. Additionally, through excessive CPU usage, you could bring real discomfort to the user due to increased fan noise.
Performance aside, the JVM’s class loader system was difficult to work with, and it was impossible to do the things I wanted in a non-clunky way. The JVM is drowned in unnecessary complexity, which I found apparent when working with its bytecode and flawed object model.
I think good engineering is important, and that means valuing efficient and simple solutions. The JVM is not that, and nor is it something that can be fixed; its problems stretch down to the roots.
Finding a Good Programming Language
At the dawn of 2023, I departed from the sweet comforts of JVM-enforced memory safety and escaped into the wilderness of systems-level languages with manual memory management.
I had briefly tried Rust in late 2021, but never again. The misguided design of this language creates tremendous friction and imposes artificial puzzles that get in the way of solving the actual problem at hand. The costs outweigh the benefits, at least in most cases, and the compile times are torturous.
So, I began to learn Zig as I set out to create a new compiler. However, it didn’t take long before my frustration with Zig’s language design reached a critical threshold. For instance, the Zig compiler treats any unused variable as an error, and that is just not the way I want to program.
I promptly adopted Odin, which has a far superior design philosophy. There is still a lot I don’t like about it—like the restrictive namespacing system—but it worked well enough for my compiler, interpreter and debugger project of the first half of 2023. Eventually, the growing project size (albeit still modest) meant that the LLVM compile times were unfortunately becoming a significant source of friction.
In the middle of 2023, I began using the Jai programming language. It is, by an order of magnitude, more well-designed and powerful than any other language in its class, thanks to a unique combination of fast compile times, powerful polymorphism, meta-programming powered by a bytecode interpreter, helpful error messages and ergonomic syntax.
Despite being rather complex, Jai actually feels very simple, uniform, and almost Lisp-like in its design. Unlike other languages, Jai spends it complexity budget wisely—in the places where the added complexity pays off the most. I am using Jai to this day and that is not changing any time soon.
But the Libraries! The Ecosystem!
One of the benefits of being tapped into the Clojure and JVM ecosystem is the access to a vast range of software libraries. However, I value that much less now than I used to in the past.
Building upon layers of abstraction can often be harmful due to the additional constraints of that abstraction. The API of a library may push you towards a design that is not optimal for the problem you are trying to solve. Also, libraries are usually designed to support a variety of use-cases, which probably means that there is more abstraction (and more features) than you truly need.
Often, I have run into trouble when my specific use-case does not fit the exact mould of the library. As a result, when going to do something specific, the library’s design may outright prevent me from doing what I want without having to fork and modify the source code—an undesirable solution that partially defeats the point of using a library in the first place.
Furthermore, I don’t tend to use a large number of third-party libraries, and many of the ones I do use could be feasibly reimplemented myself. I’d say writing that extra code is worth it in many cases, especially where the library in question is simple or only a small subset of it is used. As a bonus, the code you write is tailored to your specific needs.
In any case, I’m of the philosophy that you shouldn’t be afraid to throw away code often. An implication of this is that code should be easy to write and refactor, and a reason for this practice is that the more you work on a project, the better of an idea you get about what your program should ultimately look like. Rather than being held back by old, uninformed code, you should have the freedom to rebuild substantial pieces from a simpler foundation backed by experience. A library is analogous to the old informed code you wrote before you fully understood your needs.
Remember: Source code you don’t own or understand is a liability; it’s good to keep things minimal.
Dynamic Code Execution
For me, the most compelling feature of the JVM was the ability to dynamically modify and inspect the live program. That said, with some work, simple hot code loading can be implemented in an unmanaged language. By not having to deal with the class loader system, it is possible to design a programming language with a much better system for dynamically loading code, tailored and fine-tuned according to how I want it. In fact, it may turn out that the simpler solution overall is to implement this stuff from scratch and bypass the complexity put forth by the JVM.
Another consideration: how dynamic do you need to be? By using self-describing objects everywhere, the JVM is highly dynamic, but at the great expense of performance. Is that trade-off worth it? I don’t think so, after having gained experience in modern unmanaged languages.
I believe it is preferable to opt-in to these dynamic runtime features in the places and times you need them. Ideally, no changes to the source code should be necessary to compile a more dynamic and introspective version of the program compared to a completely static version. Additionally, in the spirit of Mouldable Development, it should be cheap to create ad-hoc tools for live visualisation, debugging, and modification of the program. The video games industry has some good examples of bespoke in-house tooling.
Conclusion
At a very bird’s-eye view, I have presented some hopefully interesting aspects of my projects. This skips over many details like the mathematics involved in typeface design as well as entire topics including the compiler implementations. Also, I haven’t touched on foundational systems such as the memory allocators and the arena allocator system that I use throughout my codebase. There is also a lot yet to talk about relating to UI event handling, caching, and layout. Maybe another day.
To wrap up, I would like to emphasise a piece of truth that I repeatedly discovered as I set down these paths of learning unfamiliar topics: the low-level details are not as frightening as they may seem at first.
When I was writing Clojure, the idea of working with JVM bytecode seemed daunting. Then, I spent time learning about it and found it was not so difficult after all.
Coming from garbage-collected languages, the idea of using a language with manual memory management sounded very tricky and error-prone, but it’s not actually that bad with the right techniques.
Learning assembly language and manually generating x64 machine code was intimidating at first, but it just takes perseverance to read through the vast Intel documentation before being able to create something simple that works. Assembly language itself is actually very simple to understand.
Learning to use a graphics API, particularly one like D3D12 or Vulkan, seemed like a monumental task due to the vast amount of prerequisite knowledge. And indeed it is, because there is no happiness to be found in modern graphics APIs. However, once you dip a foot in and start learning, you start to pick things up, things get more familiar, and thus things get a bit easier.
Not everything is like this—some things are just really difficult and may even take a lifetime to master. For instance, I’ve made no attempt at an optimising compiler because there is no limit to how complicated that gets when taken to the fullest extent (see LLVM). Also, when working with modern graphics APIs like D3D12, even industry professionals are prone to make subtle memory management mistakes thanks to the overly convoluted nature of these APIs.
But for many things, all it takes is the initial step of dipping your toes in the water, then as you begin uncovering new territory, everything becomes a lot clearer and less daunting.